Summer Challenge on Writer Verification, under NCVPRIPG'23
Challenge Updates
- Registrations are now closed
- Semi-final dataset released
- Semi-finals over
- Top-6 qualifying teams announced
- Write-up submission closed
- Event schedule updated
- Challenge Convened
Challenge gallery

Girin Chutia, 1st Runner Up, presents his submission and methodology used.

Dr. Anand talks about the challenge and the data creation process.

Manan Shah (IIT Mandi) emerges as the winner of the challenge, receives a certificate from Dr. Santanu Chaudhury (Director, IIT Jodhpur).

Arvind Kumar Sharma (IIT Jodhpur) emerges as the 2nd Runner Up of the challenge, receives a certificate from Dr. Santanu Chaudhury (Director, IIT Jodhpur).

Invited Guest talk on Online Signature Verification by Dr. Suresh Sundaram.

Invited Guest talk on Online Signature Verification by Dr. Suresh Sundaram.

Finalists of the challenge present their work and methodology.

Wonderful audience at the challenge event.

Wonderful audience at the challenge event.
Challenge
Welcome to the Summer Challenge on Writer Verification, hosted as part of the National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG'23). Given a pair of handwritten Hindi Text images, the task is to automatically determine whether they are written by the same writer or different writers.
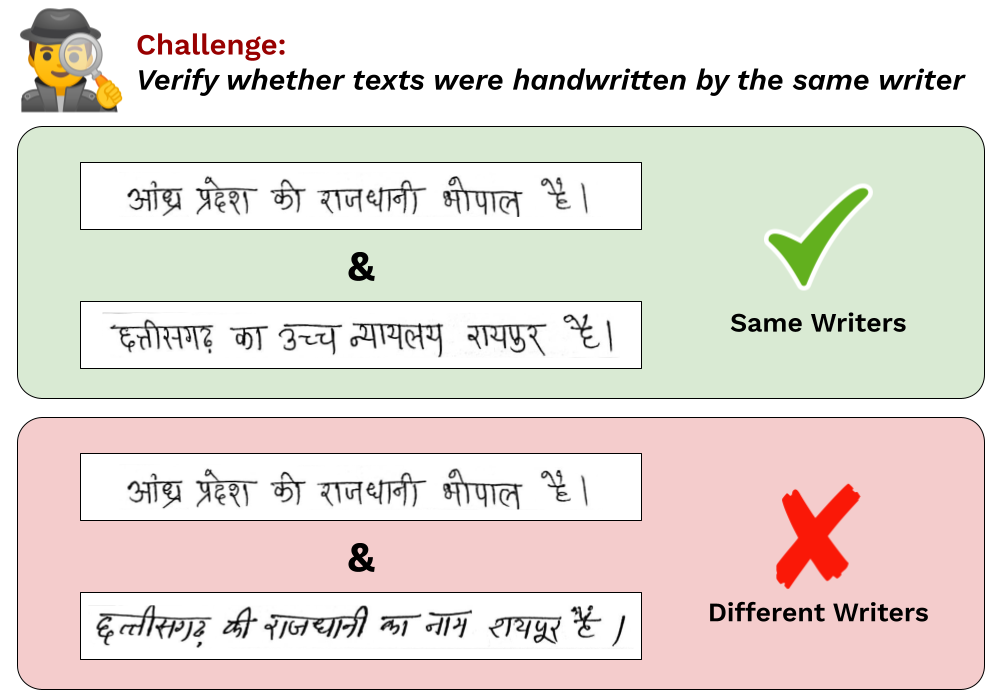
Writer Verification task originated as a signature verification problem to flag potentials frauds in banking-sector. This is a challenging task as the individual handwriting can significantly vary from person to person and thus the underlying model needs to learn the varations in the handwriting style. The problem becomes even more complex in the offline setting, where the dynamic information about the writing process is not available (like writing in an electronic equipment).
Evaluation metrics
Following the literature on verification tasks, we shall use the following performance measures:
- F1
- AUC
The Area Under the Curve (AUC) is a metric that measures the performance of a binary classification model by calculating the area under the receiver operating characteristic (ROC) curve. The AUC ranges from 0 to 1, where a score of 1 indicates a perfect classifier, while a score of 0.5 indicates a random classifier. Note that the Leaderboard will be decided based on the AUC score only.
Input and output specifications
Training set contains 1352 folders of images. All the images in one folder are
written by the same
person.
Validation set contains a set of images from 92 different writers. The val.csv file contains name of
image pairs
and the corresponding labels. A label of 1 indicates that the images are written by the same writer
and a label of 0
indicates that the images are written by different writers.
For futher details, please refer to
the
Github repository.
Test set contains images from 360 writers. In test.csv you are given name of image pairs. For output, you need to predict the label for given pair of images and submit the csv file in the format by editing the test.csv file. Note that test set will be released at a later date than train and validation set.
Code to get started
A github repository is provided to get started with the challenge. The repository contains a sample code to read the dataset and evaluate the performance and other necessary instructions.
Dataset
Dataset description here
The dataset for consists of handwritten text images in Hindi. The problem is to identify whether writer of a given pair of images are same or not. The dataset is divided into three folders: train, test, and val.
- The train folder contains 1352 subfolders, where each subfolder represents a different writer. The images in each subfolder are samples of handwritten text written by that particular writer.
- The val folder contains 730 handwritten text images from 92 writers. Additionally, you will be provided with a val.csv file, which contains the labels for the validation data. Each row in val.csv contains the names of an image pairs followed by a label (1 or 0), indicating whether the two images were written by the same writer or different writers.
- The test folder contains 2926 handwritten text images from 360 writers. You will also be provided with a test.csv file, which does not contain any labels. Your task is to predict the writer for each image in the test dataset.
Training Dataset
Google Drive link will be provided in the mail
Validation Dataset
Google Drive link will be provided in the mail
Testing Dataset
Google Drive link will be provided in the mail
Leaderboard
Test leaderboard
| Team | AUC |
|---|---|
| MaSha | 0.976 |
| InkSq | 0.922 |
| Neural Survivor | 0.915 |
| Forza Code | 0.912 |
| Alpha | 0.878 |
| Word Detective | 0.820 |
| Baseline | 0.650 |
Events schedule
When: July 21, 2023; 1730-1930 IST
| Time slot (in IST) | Activity | Speaker |
|---|---|---|
| 1730-1735 | Welcome and Introduction | Organizing team |
| 1735-1745 | Task Dataset and Challenge Overview | Dr. Anand Mishra |
| 1745-1815 | Invited Talk: "Catch me if you can; Writer verification in offline signatures" | Dr. Sounak Dey, AI Research Engineer, Helsing AI |
| 1815-1845 | Invited talk : "Elastic matching algorithms for online signature verification" | Dr. Suresh Sundaram, IIT Guwahati |
| 1845-1850 | Winner Announcement | Dr. Anand Mishra |
| 1850-1920 | Team presentations | ~ |
| 1920-1925 | Closing remarks | Dr. Anand Mishra |
Events timeline
| Event | Deadline |
|---|---|
| Challenge announced | April 14, 2023 |
| Release of Training and validation Data | April 14, 2023 |
| Registration Closes | April 30, 2023 |
| Release of Test Data (for semifinal) | June 29, 2023 |
| Last date for submitting the results (for semifinal) | June 30, 2023 |
| Last date for submitting the trained model | June 30, 2023 |
| Last date for submitting the inference model | June 30, 2023 |
| Leaderboard updates (for semifinal) | July 1, 2023 |
| Last date to submit a writeup about the submitted solution | July 10, 2023 |
| Release of test data (for finals) | July 16, 2023 |
| Last date for submitting the results (for final) | July 16, 2023 |
| Announcement of final winners | July 21-23, 2023 (during conference) |
| Closing of the competetion | July 23, 2023 |
Registration
Registrations are now closed.
Challenge Rules
- This challenge is open to all (students and professionals)
- Participants can either register as a solo particiapnt or can form a team.
- Rules for team formation:
- A team can have a maximum of 4 participants
- Team members can be from same or different organizations/affiliations
- A participant can only be a part of a single team
- Only one member from the team has to register for the challenge
- One team can only have one registration. Multiple registrations can lead to disqualification.
- There is no limitations on the number of teams from the same organizations/affiliations (However, one participant can only be part of an unique team)
- Data download will be permitted only after the team has completed the registration
- Attending conference (NCVPRIPG'23) will be highly encouraged. Only attending team will get the certificates and awards.
- The evaluation will be done in two stages: Semifinal (Online) and Final (in-person). Only top-performing teams will be invited to participate in the final evaluation that will be held during the conference. In the case of ties, the organizing committee may rank teams based on the method’s novelty and readability of codes. The organizing committee’s decision in this regard will be final.
Awards and Recognition
- Cash prizes(in INR)*:
- Winner: 15K
- First Runner-up: 10K
- Second Runner-up: 5K
- Free registration to top-5 teams in NCVPRIPG'23
- Opportunity for summer internship in IITJ
- Paper writing collaboration
- Certificate to each participant
(*It is mandatory to attend the NCVPRIPG'23 in person in order to be eligible for the prize and certificates.*)



